로컬에서 LLM을 돌려봅시다.. (1) LAMMA 그리고 그 이후
요즘 LLM이 엄청 핫합니다. 페이스북에서 LAMMA 모델을 유출? 또는 공개를 한 이후, 또 ChatGPT의 막대한 성공 이후에 ChatGPT까지는 아니더라도 적은 컴퓨팅 파워로 어느정도의 성능을 원하는 사람들이 많아지고 있습니다. 앞으로 이런 사람들이 많은 만큼, 더 작은 모델들을 위한 연구가 계속 진행될 것으로 생각됩니다.
작게나마 현재 LLAMA(Large Language Model Meta AI)를 비롯해서 현재 어떻게 되어가고 있는지를 정리해 보도록 하겠습니다.
1. LLAMA
메타 (구 페이스북)에서 만든 작은 언어 모델. Open Source 로 만들었지만 실제로 weight을 다운받으려면 메타에 waitlist을 등록해야 됩니다. 65B, 33B, 13B, 7B 네 가지 정도의 모델이 있습니다. GPT4는 100 Trillion parameter가 있다고 알려져 있고, GPT3같은 경우 175B의 파라미터 갯수가 있다고 합니다. 다만 pretrained된 모델만 공개하였기 때문에, 결국 fine-tuing은 알아서 진행해야 됩니다. ㅎㅎㅎ
2. ALPACA
github : https://github.com/tatsu-lab/stanford_alpaca
blog 글 : https://crfm.stanford.edu/2023/03/13/alpaca.html
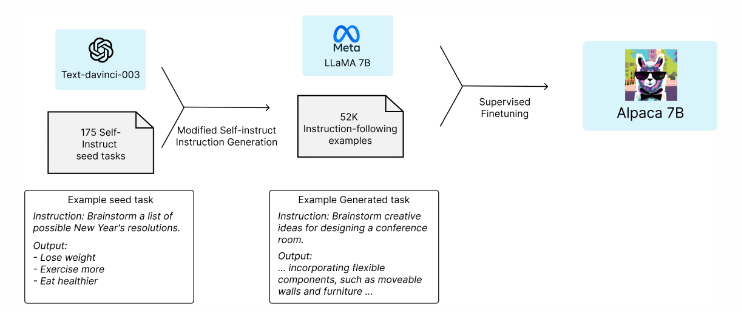
블로그 글에 따르면, gpt3.5와 비슷한 정도의 수준을 가진다고 합니다. Fine-tuning에는 A100 8대를 사용해서 3시간 정도가 걸렸다고 합니다. GPU Ram으로 80GB정도가 필요하다고 하더군요.
3. ALPACA-LORA
reference: https://medium.com/serpdotai/lora-low-rank-adaptation-of-large-language-models-82869419b7b8
논문 링크 : https://arxiv.org/abs/2106.09685
Low-rank adaptation의 논문을 사용해서, 수학적으로 low-rank의 weight들만을 계산함으로 인해 많은 정보를 loss하지 않으면서 적은 리소스를 사용하는 방법입니다.
4. LLAMA.CPP
Github : https://github.com/ggerganov/llama.cpp
Github Discussion : https://github.com/ggerganov/llama.cpp/discussions/406
지금 현재 사람들이 가장 관심있어하는 방법 중 하나로, weight을 bin 파일로 변환해서, CPU로도 돌아갈 수 있도록 만든 프로젝트입니다.
C/C++과 Python binding을 통해서 Python으로도 돌릴 수 있습니다. GPU가 필요가 없는 만큼, 라즈베리 파이 등 극단적으로 컴퓨팅 리소스가 제한된 환경에서도 돌아갈 수 있는 있는 사례들도 계속 나오고 있습니다.
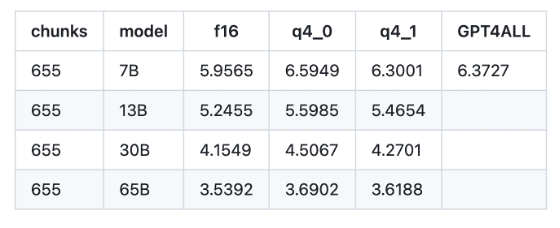
그리고 quantize (경량화)를 하면서 더더욱 컴퓨팅 리소스를 줄일 수 있습니다.
다음 표는 perplexity에 대한 표이고, 작을수록 더 좋은 성능을 나타냅니다.
5. GPT4ALL
- Nomic AI에서 개발한 프로젝트로서, GPU와 CPU둘 다 개발이 가능합니다.
- LLAMA 7B Alpaca-lora (4.2GB for quantized model)에 기반을 둔다고 합니다.
- A100 8개로 8시간 finetuning을 한 것으로 보입니다.
- finetuning에 $800 정도, OpenAI api call로 $500 정도 들은것으로 보입니다.
- bin 파일을 다운받을 수 있어서 쉽게 사용할 수 있습니다.
그 이외에도 너무도 많은 모델들이 있으며, 웹 서비스들과 합친 프로젝트들도 계속 생겨나고 있습니다.
AutoGPT, privateGPT, RedPajama 등등..
그리고 LangChain등 새로운 서비스도 나오고 있습니다.