ML Pipeline - TensorFlow Extended 억울해서 올리는 후기
Machine Learning 관련해서 Cloud에 pipeline을 올리는 일을 하려고 하는데, TFX를 사용해서 하고싶다는 욕구가 강하게 들었습니다. 그 이유는 W&B Seminar를 갔었는데, TFX를 사용하는 게 좋다고 말을 많이 들었기 때문이죠. Etri의 박찬성 연구자분이 하시는 세미나를 듣고, 잘 모르지만 써보고 싶다는 욕구가 강하게 들어서, 한번 사용해 보았습니다.
하지만.. 현실은.. 좋지 않았습니다.
그럼 TFX가 무엇인가? 에 대해서 간단하게 말씀드리자면, TFX 는 프로덕션 ML 파이프라인을 배포하기 위한 End to End platform입니다.
한 마디로, 코드 component 들을 모아놓은 라이브러리들의 합 (그래서 플랫폼) 이라고 할 수 있습니다.
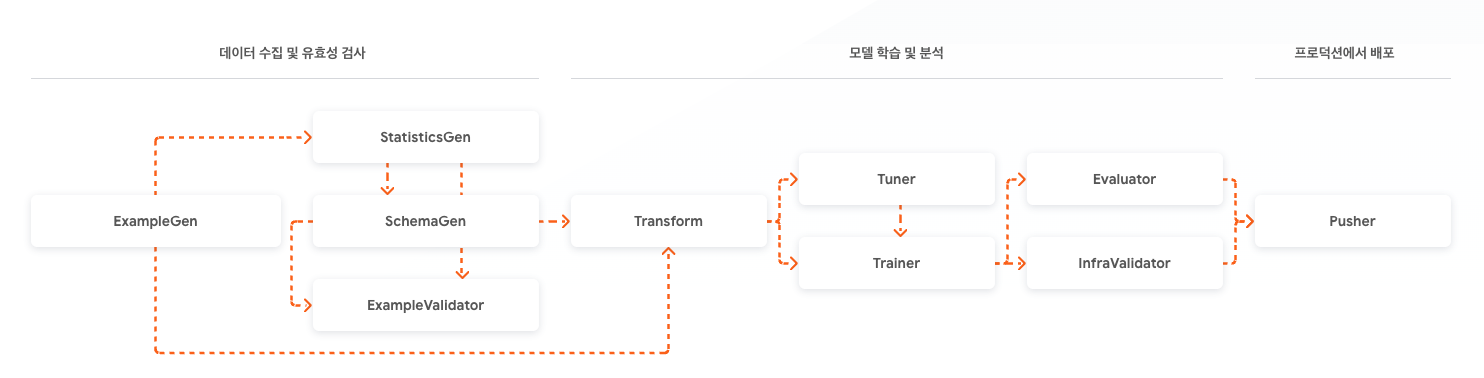
결국 로컬에서 사용할 수도 있고, GCP pipeline들과도 상당히 자연스럽게 결합될수 있다는 말에 혹해서 사용하기로 하였습니다. 하지만.. 사용하면서 여러가지 문제들을 마주하였습니다.
1. Document들의 부재 - TFX homepage 말고는 딱히 Document 를 찾을 수가 없었습니다. 각각의 component들에 대해서도, 어떤 식의 customization을 할 수 있고, parameter에는 어떤 것들이 있으며, 각각의 parameter가 무엇을 의미하는지도 제대로 알 수가 없었습니다.
2. TFX library의 install 문제 및 호환성 이슈 - pip install tfx를 하면 한시간이 넘는 시간동안 설치를 해도 안되는 이슈가 있었습니다. 결국 어떤 TFX 라이브러리를 설치하느냐에 따라서 그 requirement들을 미리 적어놓은 파일들을 설치하는 방법으로 이 이슈를 해결합니다. 관련된 링크 입니다. https://stackoverflow.com/questions/68810562/pip-install-tfx-taking-way-too-long , https://github.com/yodiaditya/datascience/tree/main/tfx 이 뿐만 아니라, TFX와 다른 라이브러리들이 호환성이 안 맞는경우가 많아서, 라이브러리가 상당히 support를 안하는구나.. 라는 인상을 많이 받았습니다. library들의 requirement가 서로 맞지 않으면, 사실 답이없습니다...
3. 1번과 연관된 내용인데, Debugging 하기가 정말 너무 힘이 듭니다. 잘 모르는 에러가 나왔을 때, TFX를 사용하는 유저도 많이 없을 뿐만 아니라 원래 어떤 식으로 나와야 하는게 정답인지 제대로 된 tutorial이 없기 때문에, Root Cause 를 찾으려면, 제대로 된 Tutorial을 참고해서 그대로 해보는 식으로 할 수 밖에 없었습니다. ChatGPT 기반의 디버깅도 제대로 통하지 않는 순간이었습니다.
여기까지는 제가 느꼈던 한계들이고, 막상 구현하면서 막혔던 부분은, Evaluator Component를 만들면서 였습니다. ExampleGen과 Trainer의 output을 넣으면 자동으로 Evaluator가 나와야되는데, 나오지 않고, 계속 이상한 에러가 나오는 것을 발견하였습니다. 처음에는 무슨 에러인지 몰랐는데 알고 보니깐 ExampleGen에서 나온 output이 expected shape 이 아니라는 것을 발견했습니다.
사실 이게 왜 이렇게 나오는지부터, 그리고 ExampleGen이랑 Trainer는 왜 되는지에 대해서도 참 쉽지 않은 것 같습니다. Evaulator가 안되는 이유에 대해서도, 제대로 디버깅을 할 수 가 없었습니다. 결국 다른 Tutorial을 사용해서 ExampleGen 의 output 을 살펴보니, 이런 식의 포맷을 할 수 있었습니다.
features {
feature {
key: "image_class"
value {
int64_list {
value: 9
}
}
}
feature {
key: "image_floats"
value {
float_list {
value: -0.5
value: -0.5...
value: -0.5
}
}
}
}
하지만 저의 파일 포맷은 이런 식이었습니다.
features {
feature {
key: "image/encoded"
value {
bytes_list {
value: "\377\330.......7\331"
}
}
}
feature {
key: "image/label"
value {
int64_list {
value: 0
}
}
}
}그래서 파일 포맷을 바꿔 보니, 7.4MB 였던 tfrecords 파일이 400MB까지 늘어나는 것을 발견하였습니다.
이쯤되서, TFX 를 포기하기로 마음먹었습니다.
TFX 대신, kubeflow를 gcp에서 사용해서 ml pipeline 을 만드는것은 생각보다 documentation 이 잘되어있어서, 이를 보고 하는것을 추천드립니다. 추가로, tfx를 사용해야되는 경우에도 stack overflow에서 답변을 찾았는데... 딱히 와닿지는 않는거같습니다. 너무 고생을 해서 그런가..
https://stackoverflow.com/questions/73512135/why-we-need-tfx-if-we-have-airflow-for-orchestration