소리를 이용한 딥러닝을 하는데 있어서 한 가지 방법은 Mel Spectrogram을 이용하는 방법입니다.
Mel Spectrogram이란, 소리의 파형을 인간이 들을 수 있는 범위로 줄인 Mel scale로 다운 스케일한 이후 그 파형을 그림으로 그린 모양이라고 할 수 있습니다.
librosa library를 이용합니다.
audio_file = "sound.wav"
y, sr = librosa.load(audio_file)
sr = 44100
mel_spec = librosa.feature.melspectrogram(y=y, sr=sr, n_fft=2048, hop_length=1024)
mel_spec = librosa.power_to_db(mel_spec, ref=np.max)
plt.figure(figsize=(8,6))
librosa.display.specshow(mel_spec, y_axis='mel', fmax=8000, x_axis='time')
plt.title('Mel Spectrogram' + audio_file)
plt.colorbar(format='%+2.0f dB')간단한 스크립트지만, 하나하나 살펴보면서 이해해보도록 하겠습니다.
1. librosa.load()
- 오디오 파일을 로드합니다.
샘플레이트는 어떻게 넣느냐에 따라서 정해집니다.
오디오는 디폴트 샘플 레이트 (22050)으로 리샘플링 됩니다.
만약 원본 샘플 레이트를 유지하고 싶으면, sr = None을 넣으면 됩니다.
이후 y, sr을 리턴하는데, y는 numpy Ndarray의 형태로 주어집니다.
y 는 floating point와 time series의 형태로 주어집니다.
2. librosa.feature.melspectrogram()
- mel spectrogram을 만듭니다.
Mel Spectrogram을 만드는 원리에 대해서는, 푸리에 변환을 이용해서
Time Domain s(t) 를 Frequency Domain S(w) 로 만든다고 합니다.
자세한 사항에 대해서는 참조를 참고하면 좋을 듯 합니다.
그 중에서도 우리는 FFT(Fast Fourier Transform)을 사용합니다.
특히, 음악이나 음성, 소리의 경우에는 Frequency 가 일정하지 않고 계속 변하기 때문에, FFT을 각각의 변하는 Frequency에 해 주어야 하는데, 이를 STFT (Short-time Fourier Tranform) 이라고 하고, 이를 계산한 그래프를 Spectrogram이라고 합니다.
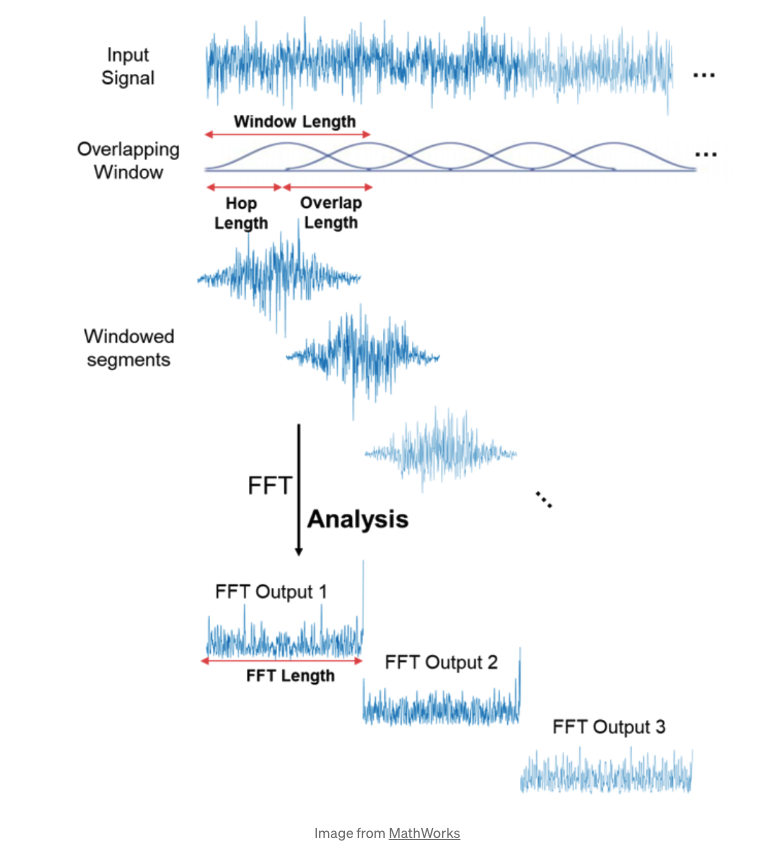
n_fft 와 hop_length의 경우에는, 한 번의 STFT를 적용하는 길이(window length) 를 말합니다. 또, hop_length는, 각각의 window 사이의 길이를 뜻합니다. 아래 그림에서 확인할 수 있습니다. 만일 hop_length가 n_fft보다 긴 경우에는, padding이 필요할 수 있습니다.
3. librosa.power_to_db():
- 소리는 압력에 따라 20 마이크로파스칼부터 20Pa까지, 백만 정도의 스케일이 있는데,
인간의 귀로 들을 수 있는 소리는 고작 작은 범위에 지나지 않는다고 합니다.
ref 로 np.max()를 넣음으로서, 소리의 최대값을 0db로 매칭시키고, 다른 값들은 -로 잡는다고 합니다.
또한, 범위의 한계가 디폴트값으로 80db로 되어있어서, -80db보다 낮은 값은 모두 -80db로 나온다고 합니다.

참조 : Understanding Mel Spectrogram , what is n_fft and hop_length in mel_spectrogram? , librosa_amplitude_to_db, 오디오 데이터 전처리
'Audio Processing' 카테고리의 다른 글
| 오디오 프로세싱 - for loop를 사용해서 오디오 자르기 (0) | 2022.07.20 |
|---|