모바일넷 구글에서 만들어진 모델로서, V1, V2, V3가 있습니다. 각각 2017년 4월(v1), 2018년 1월(v2), 2019년 5월(v3) 입니다.
컴퓨터 비전에서 중요한 모델이고, mobilenet은 CNN의 한 종류로서, CNN을 제대로 알고 이 리뷰를 보는걸 권합니다.
Mobilenet V1의 핵심 개념
Mobilenet V1 의 핵심개념은 Depthwise Seperable Convolution, Pointwise Convolution 입니다. 그리고 두개의 새로운 hyperparameter - width multiplier 와 resolution multiplier를 도입합니다. 결론적으로, accuracy를 조금만 희생을 하더라도, speed를 올릴 수 있으면 좋겠다고 생각을 합니다.
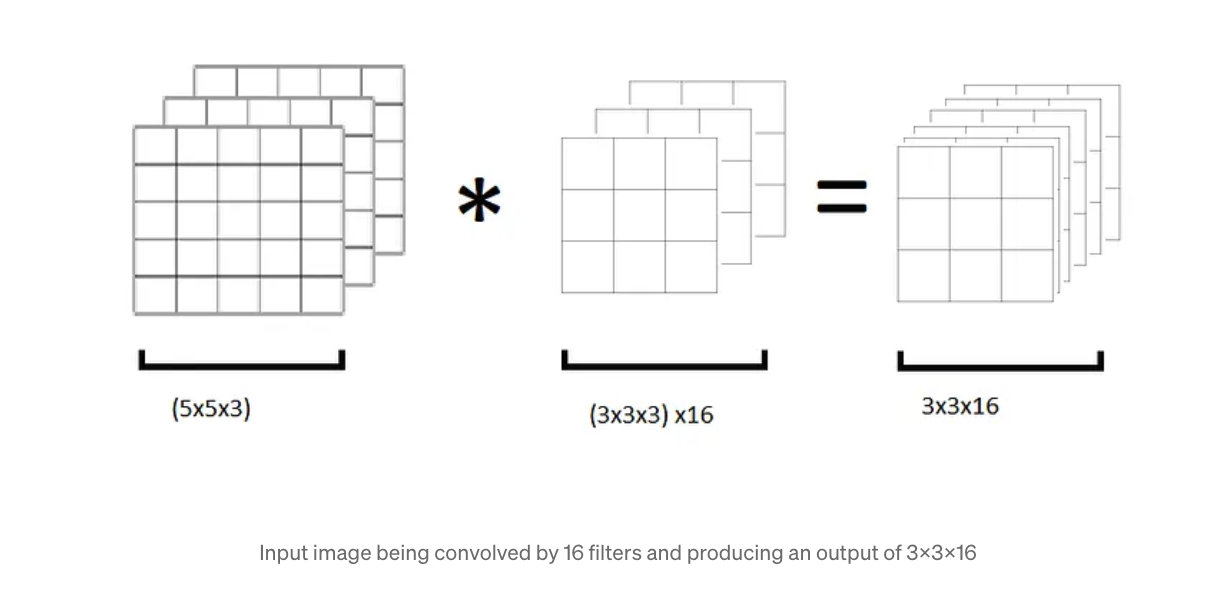
위 그림에서 볼 수 있지만, standard convolution을 통해 computational cost가 얼마나 발생하는지에 대해서
알아봅시다.
computational cost = filter_height * filter_width * num_of_input_channels * num_of_filters * output_height * output_width
위 그림의 사진의 예를 보면, 3x3x3x3x3x16 = 3888 개의 연산이 필요합니다.
이를 두 가지 Depth-wise seperable Convolution, Pointwise Convolution 로 나눠서 볼 때,
Depthwise seperable Convolution의 경우, 여러 개의 필터들을 하나로 만들어서 계산을 하는 내용입니다.
고로, 다음과 같은 계산이 나옵니다.
computational cost = filter_height * filter_width * num_of_input_channels * output_height * output_width

그림의 예와 같이, 3x3x3x3x3 = 243 번의 연산이 필요합니다.
Depthwise seperable convolution은 획기적으로 연산을 줄여주지만, filter를 사용해서
우리가 원하는 feature를 뽑아내지 못한다는 큰 단점이 있습니다.
논문을 인용하자면,
Depthwise convolution is extremely efficient relative to standard convolution. However it only filters input channels, it does not combine them to create new features. So an additional layer that comnputes a linear combination of the output of depthwise convolution via 1x1 convolution is needed in order to generate these new features.
이게 곧 mobilenet의 핵심 개념이라고 생각합니다. 즉, convolution을 convolution matrix로 하는게 아닌, 1x1 filter를 사용하는 것을 말합니다. 그리하여 standard convolution의 computational cost 가
DK · DK · M · N · DF · DF
에 비해, Depthwise and pointwise convolution의 경우
DK · DK · M · DF · DF + M · N · DF · DF
가 나옵니다.
DK : kernel's spatial Dimension
M : # of input channels
N : # of output channels
DF : Feature map's spatial Dimension
그리하여 standard convolution과 비교하면, 위에서 계산한 것과 같이 3888번의 연산에 대비해서,
computational cost = 1x1x3x3x3x16 = 432 번의 연산이 필요함을 알 수 있습니다.
결론적으로 total computational cost의 경우에는, 243 + 432 = 675 번의 연산이고, 결론적으로 82.6 %의 연산을 줄일 수 있다는 결론이 나옵니다.
그 이외에도 두 가지의 parameter를 소개합니다.
1. Width Multiplier : Thinner Models - α
α는 0과 1 사이의 파라미터로, input channel, output channel의 값을 조절합니다.
연산의 숫자는 α의 제곱에 반비례 합니다.
2. Resolution Multiplier : Reduced Representation - ρ
ρ는 보통 {224, 192, 160, 128} 등의 범위 안에 있고, resolution 즉, 들어오는 이미지의 값을 조절합니다.
연산의 숫자는 ρ의 제곱에 반비례 합니다.
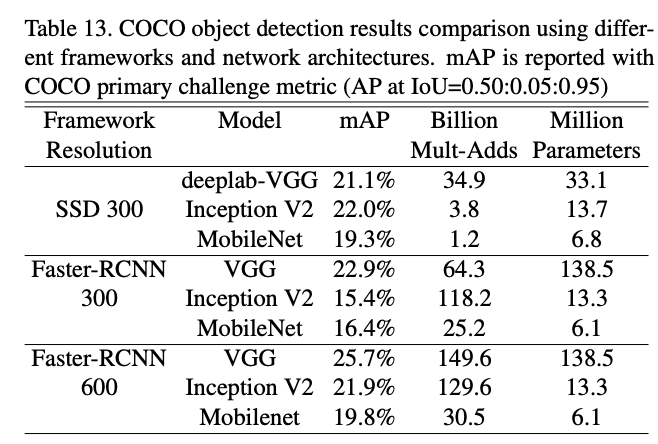
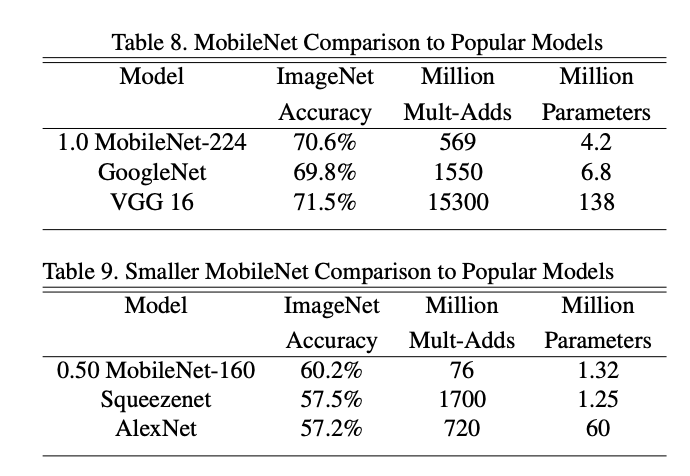
Mobilenet을 백본으로 여러가지 작업을 수행할 수 있습니다. 예를 들어서, face attributes, object detection, face embedding, classification 등이 있습니다. 그리고 결과는 다음과 같습니다. 물론 논문 자체가 오래된 논문이라서 비교하는 모델들도 모두 오래된 모델들이지만, mobilenet이 더 연산이 작은데도 성능이 비슷하거나 오히려 더 좋은 경우도 있어서 괄목할 만한 성과라고 생각합니다.
참고자료 :
1. mobilenet 논문 : https://arxiv.org/abs/1704.04861
2. mobilenet v1 explained : https://medium.com/mlearning-ai/explained-mobilenet-v1-bb700abfe824
3. 한글 자료 mobilenet v1 : https://greeksharifa.github.io/computer%20vision/2022/02/01/MobileNetV1/
'Deep Learning' 카테고리의 다른 글
| Yolov5 Tflite 버전을 local desktop에서 돌리면 느려지는 이유 (1) | 2023.02.13 |
|---|---|
| Pytorch를 이용한 Quantization (0) | 2023.01.25 |
| Pytorch에서 Batch Size 1로 했을 때 accuracy가 떨어지는 문제 해결 (model.eval()) (0) | 2022.09.23 |
| 오디오 딥러닝을 해봅시다! (Sound Classification) - 2. 모델을 이용해서 학습하기 (0) | 2022.09.08 |
| 오디오 딥러닝을 해봅시다! (Sound Classification) - 1. 데이터 전처리 (0) | 2022.09.06 |